
From Code Generation to Application Generation, Part 4: My Coding Agents Are Productive. I Am Exhausted.
Published:
In Part 3, I explained why I stopped looking at generated code.
Like many engineers adopting AI-assisted development, I initially reviewed almost everything the coding agent produced. Over time, as the models improved and my validation process matured, I found myself spending less time reviewing implementation details and more time validating outcomes.
The goal shifted from reviewing code to validating applications.
That worked surprisingly well.
Unfortunately, it created a problem I never expected.
I suddenly had free time.
The Core Problem
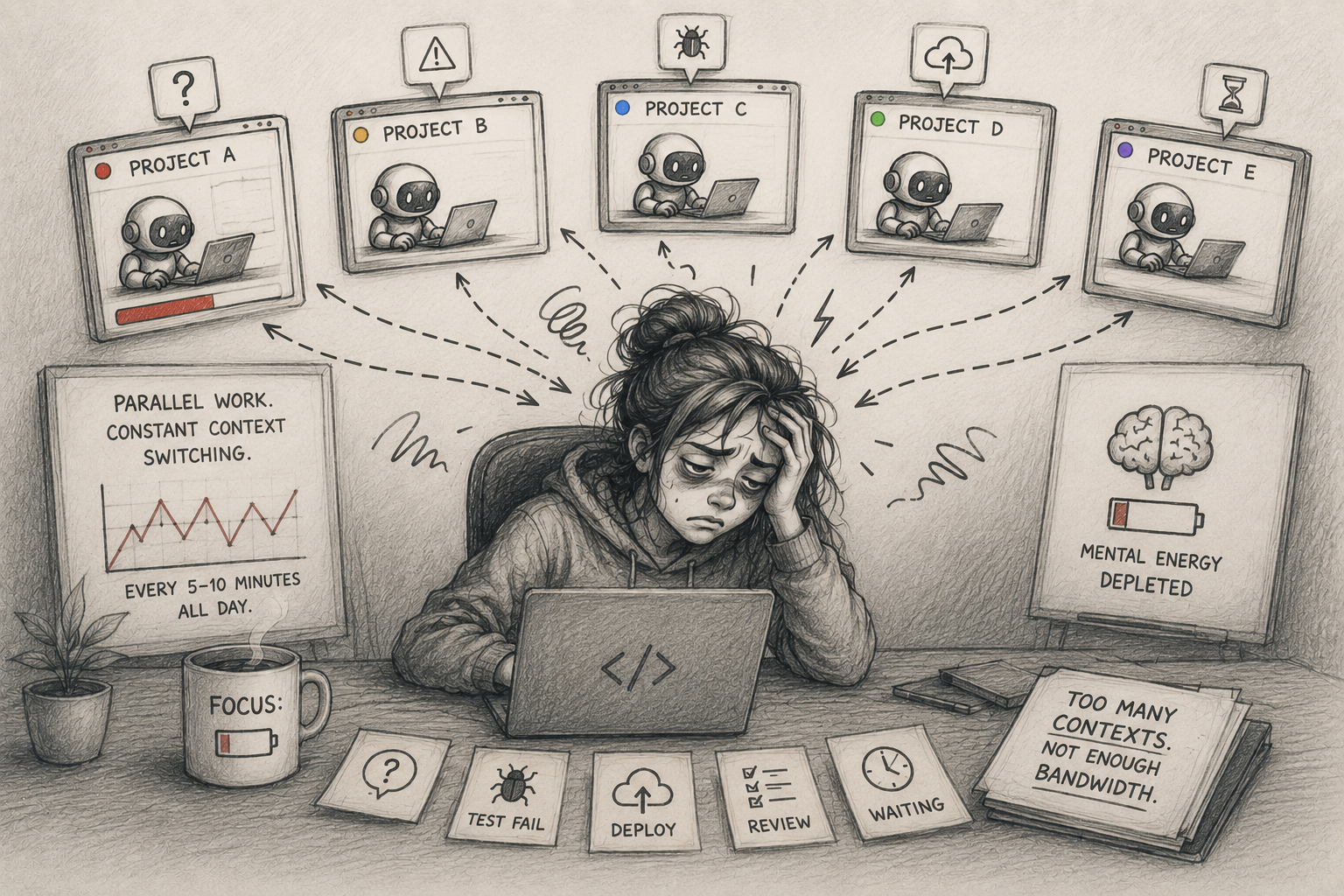
AI coding agents make implementation faster, but they also increase the number of active projects one person can supervise. That shifts the bottleneck from coding to context management.
The agent writes code.
The human reloads context, makes decisions, resolves ambiguity, evaluates validation results, and decides what should happen next.
After a few hours, the surprising problem is not lack of productivity.
It is exhaustion.
The First Time in My Career
For most of my career, software development looked something like this:
I worked on a project.
I implemented a feature.
I tested it.
I moved to the next task.
Sometimes I was blocked waiting for another team.
Sometimes I was waiting for a deployment.
Sometimes I was sitting in meetings wondering why we needed six teams to add a single field to a database.
But regardless of the process, my attention was usually focused on one project at a time.
Coding agents changed that.
Now I give an agent a task.
It starts generating code.
While it is working, I have a few minutes available.
Naturally, I open another project.
That project gets a task too.
Now I have more free time.
So I open a third project.
Then a fourth.
Then a fifth.
At some point I look at my desktop and realize I have become the coordinator of a small army of coding agents.
The agents seem happy.
I am not.
The Cost of Parallelism
When people talk about AI-assisted development, the conversation is usually about productivity.
How many lines of code can be generated?
How much faster can features be delivered?
How many developers can be replaced?
I think we are missing a more interesting question.
What happens to the human?
Because after a few hours of working this way, I noticed something strange.
I was exhausted.
Not because I was coding.
I was not coding very much.
I was switching contexts.
Project A is generating code.
Project B is running tests.
Project C is waiting for a validation decision.
Project D needs clarification.
Project E just finished a deployment.
By the time I remember what Project A was trying to accomplish, Project C is asking for my attention again.
The coding agent is doing the coding.
I am doing the context switching.
And context switching turns out to be surprisingly expensive.
This Is Not Normal Context Switching
At first, I assumed I was experiencing the same problem engineering managers, staff engineers, and tech leads have always faced.
After all, software engineers have always switched contexts.
We move between meetings, code reviews, design discussions, production incidents, mentoring, and implementation work.
The difference is cadence.
Traditionally, context switches happen every thirty minutes, every hour, or a few times throughout the day.
You have enough time to load a problem into your head and make meaningful progress before moving on.
Working with coding agents feels different.
The context switches are smaller, faster, and far more frequent.
A coding agent asks a question.
A deployment finishes.
A validation fails.
A test suite completes.
Another project needs a decision.
Ten minutes later the cycle repeats.
Then repeats again.
And again.
The implementation work is happening in parallel.
The human coordination work is happening continuously.
What surprised me was not the amount of work.
It was the frequency.
For the first time in my career, I found myself reloading completely different technical contexts every few minutes for hours at a time.
Eventually I realized that I was not managing projects.
I was managing context transitions.
And those transitions were becoming the most expensive part of my day.
We Were Never Trained For This
What makes this particularly interesting is that software engineering has spent decades optimizing for parallel execution.
Distributed systems.
Parallel processing.
Microservices.
Cloud computing.
We have become remarkably good at designing systems that do many things simultaneously.
Humans, however, have not changed nearly as much.
For most of my career, I operated with what I would call a single active technical context.
Even when multiple projects existed, I was usually focused on one of them for a meaningful period of time.
I loaded the context into my head.
I worked within that context.
Then I moved to the next thing.
Coding agents changed the economics.
The implementation may be happening in parallel, but human understanding still takes time.
Project A requires one mental model.
Project B requires another.
Project C has different assumptions, different architecture, and different decisions.
The agents seem perfectly comfortable operating in parallel.
Meanwhile, I am constantly unloading one context and loading another.
Maybe future engineers will adapt naturally to this style of work.
Maybe new tools will emerge.
But right now it often feels like I am using a human brain optimized for sequential work to supervise a highly parallel execution environment.
My Current Solution: Do Not Close Anything
There are already tools attempting to solve this problem.
Some save conversations.
Some save sessions.
Some promise that context can be restored later.
Maybe they work.
Maybe I am overly cautious.
For now, my strategy is embarrassingly simple.
I do not close anything.
Every terminal stays open.
Every repository stays open.
Every browser tab stays open.
Every conversation stays open.
Why?
Because I do not completely trust that I will be able to reconstruct the exact state of the project later.
I know which terminal is deploying.
I know which session contains the architectural discussion.
I know where the failing validation lives.
Closing it feels risky.
The result is a desktop that increasingly resembles an air traffic control center.
At some point, finding the correct terminal window becomes harder than solving the technical problem I originally opened it for.
That seems like a sign that something is missing.
We Have Coding Assistants. We Do Not Have Context Assistants.
Today’s AI tools are remarkably good at helping us generate code.
What they are not particularly good at is helping us manage multiple active streams of work.
Imagine a system that could answer questions like:
- What is every coding agent currently working on?
- Which projects are waiting for my attention?
- Which projects are blocked?
- What was the last significant decision made in each project?
- What should I work on next?
That does not sound like a coding assistant.
It sounds like a context assistant.
And I suspect that category of tools is going to become increasingly important.
Then I Noticed Another Problem
While struggling with context switching, I started noticing something else.
The coding agents were learning useful lessons.
Unfortunately, those lessons stayed trapped inside individual projects.
For example, one of my projects generates PDF reports.
The PDFs technically worked, but they had large amounts of unnecessary whitespace.
The output looked awkward.
So I added a validation rule specifically designed to detect that issue.
The coding agent adapted quickly.
The PDFs improved dramatically.
Problem solved.
Or so I thought.
A few days later I remembered that I had several other projects generating PDFs.
The exact same improvement would be valuable there too.
And suddenly I had another decision to make.
Do I create a reusable skill?
Do I manually update every project?
Do I ask another coding agent to update multiple repositories?
None of these options felt particularly satisfying.
The lesson had been learned.
The challenge was sharing it.
Learning Is Becoming More Valuable Than Coding
This is where I think something interesting is happening.
Current coding agents are very good at generating solutions.
What they are not particularly good at is managing organizational learning.
Humans naturally recognize patterns.
We notice when a validation rule, architectural decision, quality gate, or workflow improvement could benefit another project.
The challenge is transferring that knowledge without creating a mountain of manual work.
As the number of active projects increases, this becomes more important.
The bottleneck slowly shifts.
Less effort is spent generating code.
More effort is spent managing context and distributing knowledge.
In other words, the difficult part is no longer building things.
The difficult part is remembering what we have learned.
What Comes Next?
When I started this series, I assumed the implementation would mostly focus on generating applications instead of code.
The more projects I built, the more I realized that code generation was only part of the story.
The bigger challenges were:
- Managing context
- Managing attention
- Capturing lessons
- Sharing knowledge
- Avoiding repeated mistakes
- Preventing improvements from becoming trapped inside individual repositories
These observations significantly influenced the architecture I eventually built.
What started as an experiment in application generation gradually evolved into an experiment in memory, validation, learning, and context management.
In the next part, I will finally walk through the implementation and explain how I approached those problems.
And yes, this time I really mean it.