
From Code Generation to Application Generation, Part 1: When Does the Agent Stop?
Published:
 One of my favorite ways to use AI is through code generation.
One of my favorite ways to use AI is through code generation.
When people discuss AI, the conversation often turns to hallucinations. Models confidently state things that are incorrect, and verifying every statement can become exhausting.
Code feels different.
When an AI generates code, I can run it. The program either produces the desired result or it does not. Unit tests can validate behavior. Integration tests can verify interactions. Even when the implementation is imperfect, there is usually a path toward measuring progress.
For a long time, this made code generation feel fundamentally different from text generation.
One of the earliest projects where I experienced this involved search query analysis for a retailer.
The goal was to identify synonyms from search logs. Customers often search for the same part using different terminology, and improving synonym coverage can significantly improve search quality.
The AI started with lexical approaches. It generated rules based on string similarity and various matching heuristics. The results were reasonable but not perfect. Whenever I pointed out incorrect matches, the AI adjusted the rules and generated a new version.
Over time, the quality improved.
At one point I suggested incorporating semantic approaches. The AI introduced embeddings and eventually proposed a hybrid strategy combining lexical and semantic signals.
The results improved again.
The code compiled.
The outputs looked better.
The implementation became more sophisticated.
Yet something felt incomplete.
The Hidden Assumption
At first, I believed code generation avoided the hallucination problem.
The AI was producing executable artifacts rather than paragraphs of text. The outputs could be validated. Incorrect behavior could be observed directly.
What I eventually realized was that a different type of hallucination still existed.
The code was often correct.
The implementation was often reasonable.
The problem was that nobody had defined what success looked like.
The synonym system could always be improved.
Another rule could be added.
Another threshold could be tuned.
Another signal could be incorporated.
Nothing in the process defined when the problem was solved.
The AI kept making progress, but neither of us knew when it should stop.
The Website Quality Tool
I encountered the same pattern again while building a website quality assessment tool.
The goal was simple. Given a small business website, the system would evaluate factors that influence trust and customer conversion.
The reports examined signals such as:
- Trust indicators
- Testimonials
- Reviews
- Contact information
- Service-area coverage
- SEO basics
- Technical quality
The first reports looked impressive.
They contained recommendations, observations, and scores.
At first glance they appeared useful.
Then I started reviewing them more carefully.
One report claimed that service-area pages were missing.
The website clearly linked to multiple service-area pages.
Another report stated that broken images were detected.
The report never identified which images were broken.
The findings sounded reasonable.
The evidence was incomplete.
The problem was not that the AI could not generate a report.
The problem was that we had never defined what a correct report looked like.
Borrowing Success Criteria
Once we realized correctness was the problem, a new question emerged:
How do we know whether the report is right?
One approach was manual review.
That works for a handful of websites.
It does not scale.
Instead, we began comparing our findings against other website quality tools.
Google Lighthouse became an important reference point.
Lighthouse does not simply produce a score.
It explains why.
A performance issue is tied to specific resources.
An accessibility issue is tied to specific elements.
The findings are backed by evidence.
That philosophy became more important than the score itself.
Every recommendation in our system needed supporting evidence.
If we reported missing testimonials, we needed to explain how we reached that conclusion.
If we reported broken images, we needed to identify the actual URLs.
If we reported missing service-area pages, we needed to show why they were considered missing.
The report became less about generating recommendations and more about generating verifiable observations.
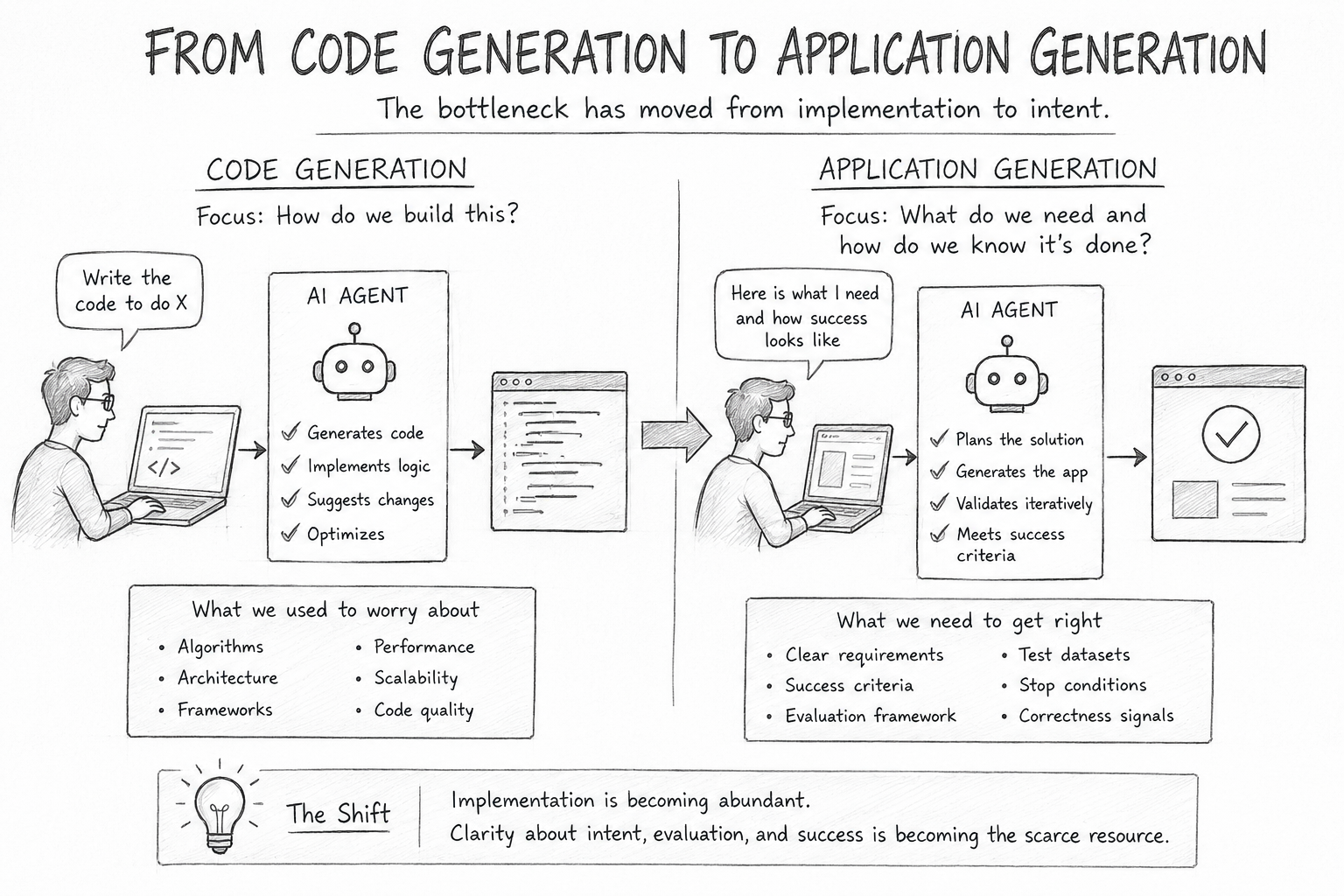
The Real Bottleneck
For decades, software engineering focused on implementation.
How should we build it?
Which architecture should we choose?
How should we deploy it?
How should we scale it?
AI changes the economics of implementation.
Code generation is becoming abundant.
Application generation is becoming possible.
As implementation becomes cheaper, another resource becomes more important.
Clarity.
The difficult question is no longer:
How do we build this?
The difficult question is:
How do we know when we are done?
Code generation is becoming abundant.
The scarce resource is clarity.
That realization kept appearing in project after project.
The next post looks at one of the first places I encountered it: a website quality assessment tool where generating reports turned out to be easy, but defining correctness was surprisingly hard.