
From Code Generation to Application Generation, Part 2: I Knew How to Fix It, But Wasn’t Sure You Wanted It Fixed
Published:
In this series, I am exploring a simple idea:
Enough of code. Let’s generate applications.
The goal is not to generate software faster.
The goal is to describe a problem, define success, and allow the implementation details to be generated automatically.
In the previous article, I discussed a surprising lesson from working with AI-generated code.
The code often worked.
The implementation often improved.
The hard problem was defining when the work was actually finished.
Success criteria turned out to be more important than implementation.
If you missed Part 1, you can read it here: From Code Generation to Application Generation, Part 1: When Does the Agent Stop?
Becoming a Human Error Transport Layer
Some of my earliest projects with coding agents involved deploying applications to cloud environments.
It had been a while since I had spent much time with cloud infrastructure, and the agents were surprisingly helpful.
They pushed me toward newer approaches such as serverless deployments, managed services, and infrastructure automation.
Most of the time, the workflow looked like this:
- Agent writes code.
- Agent commits code.
- CI/CD pipeline runs.
- Build fails.
- I copy the error message.
- Agent fixes the issue.
- Agent commits again.
- Another build starts.
Repeat.
At some point I realized something strange.
I was not really debugging.
I was not writing code.
I was not designing solutions.
I was acting as a transport layer between GitHub Actions and the agent.
The build already knew what failed.
The agent knew how to fix many of the failures.
Why was I manually copying messages between them?
The Obvious Next Step
Once I noticed this pattern, it became difficult to ignore.
Why shouldn’t the agent watch the build?
Why shouldn’t the agent inspect deployment logs?
Why shouldn’t the agent attempt fixes automatically?
Why shouldn’t the agent retry until it either succeeds or requires information that only a human can provide?
Instead of:
Build fails
↓
Human reads error
↓
Human copies error
↓
Agent fixes error
Why not:
Build fails
↓
Agent investigates
↓
Agent fixes
↓
Build retries
The human should only be involved when:
- business decisions are required
- requirements are ambiguous
- success criteria are unclear
- additional information is needed
Everything else should be automation.
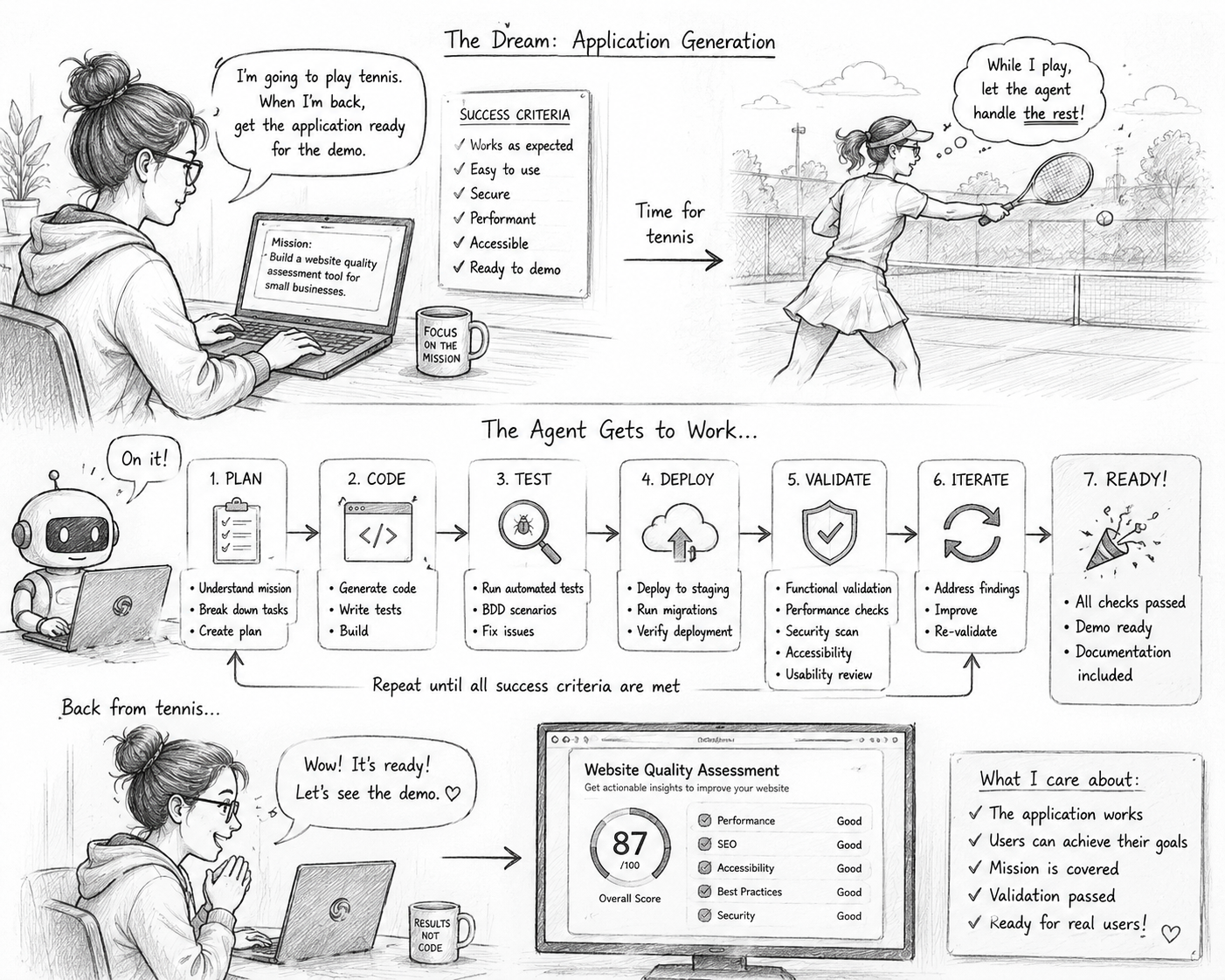
The Dream
This led me to imagine a different workflow.
I describe a problem.
I describe what success looks like.
The agent creates the application.
The agent deploys it.
The agent validates it.
The agent fixes issues.
The agent prepares a demo.
While I go play tennis.
When I return, I review the result.
Not the code.
The result.
This is the vision behind application generation.
The implementation becomes an internal detail.
The application becomes the product.
Why This Is Hard
Unfortunately, generating code is only a small part of software delivery.
Even if the agent can implement every feature correctly, many other questions remain.
Can the software be deployed?
Is it secure?
Will users understand how to use it?
Does it follow accessibility guidelines?
Is it reliable?
Can failures be detected?
Can failures be recovered from?
Historically, these concerns were scattered across different activities:
- testing
- quality gates
- code reviews
- usability reviews
- accessibility checks
- security reviews
- deployment validation
The problem is that most of these activities focus on implementation details.
Application generation requires us to think differently.
We need a way to validate outcomes rather than artifacts.
Beyond BDD and Quality Gates
While working on the MDE framework, I initially relied on two concepts:
- BDD passes
- Quality Gate passes
The idea was simple.
Generate the solution.
Run the BDDs.
Run the Quality Gate.
If everything passes twice, exit the phase.
The approach worked.
Until it didn’t.
BDDs verified functionality.
Quality Gates verified implementation quality.
Neither fully answered the larger question:
Is the application actually ready?
A project could pass all BDDs and still have:
- confusing workflows
- inaccessible interfaces
- misleading UI
- poor usability
- security concerns
- weak mission coverage
The implementation was correct.
The application was not.
Validation Becomes the Product
This realization led to a broader validation model.
Instead of asking:
Did the code pass?
We started asking:
Is the application ready?
That question requires multiple perspectives.
Functional validation.
Technical validation.
Usability validation.
UI standards validation.
Mission coverage validation.
Project-specific validation.
The exact tools vary by project.
The categories remain consistent.
A search engine should not be validated the same way as a mobile application.
A mobile application should not be validated the same way as a website assessment tool.
The validation strategy must adapt to the mission.
From Code Quality to Application Quality
Traditional software engineering optimizes implementation.
Application generation optimizes outcomes.
That sounds like a small difference.
It is not.
The moment we stop caring primarily about code, we start caring about something much larger.
Did we solve the problem?
Did we satisfy the mission?
Can users succeed?
Can the business succeed?
Can the application survive in the real world?
Those questions matter far more than whether a particular class or function was implemented elegantly.
What Comes Next?
One of the most surprising changes in my own workflow is how little time I spend looking at generated code.
In many projects, I care far more about:
- whether the application works
- whether users can complete their goals
- whether the mission is covered
- whether validation passes
The code increasingly feels like an implementation detail.
In the next article, I’ll explore that shift in more detail:
Why I Stopped Looking at Generated Code